Ce que nous observons chaque jour en pratique : en radiologie, le diagnostic est rarement le principal goulet d’étranglement. Regarder les images et poser un diagnostic peut aller étonnamment vite. Formuler le compte rendu avec les mots justes, le relire et le retoucher à la main prend souvent davantage de temps.
La reconnaissance vocale utilisée aujourd’hui dans de nombreux services de radiologie, le plus souvent Dragon Medical, SpeechMagic ou SpeechKit, ou un autre moteur médical intégré au RIS, au PACS ou au logiciel de compte rendu, est devenue très performante. Elle suit la voix du radiologue sans effort. Et pourtant, chaque jour, nous voyons les mêmes erreurs prévisibles corrigées à la main, compte rendu après compte rendu. À cela s’ajoute le compte rendu structuré (structured reporting) : choisir un modèle à la main, cliquer dans le bon champ, dicter ce champ, cliquer sur le suivant. Champ après champ.
Chaque geste prend peu de temps isolément. Ensemble, ils coûtent une chose que l’on ne veut pas perdre : l’attention portée aux images. L’attention du radiologue est encore en partie prise par la formulation, alors qu’elle devrait être pleinement disponible pour les images. Nous le voyons autant chez les internes que chez les radiologues expérimentés qui dictent au quotidien depuis vingt ans.
Le compte rendu, c’est plus de travail qu’il n’y paraît
Ce que la littérature montre est plus nuancé que le slogan « les radiologues regardent des images toute la journée ». Une étude time-and-motion de Lee et collègues (Curr Probl Diagn Radiol, 2017, publication en ligne en 2016) a observé, à un poste universitaire de neuroradiologie, le fellow principal (radiologue en formation) passer environ 54 % de son temps à l’interprétation des images, et environ 20 % à des tâches hors image comme les appels téléphoniques, les consultations et le choix du protocole d’examen. Le recensement de la main-d’œuvre en Australie et en Nouvelle-Zélande de 2020, portant sur plus de mille radiologues, est arrivé à environ 49 % de la semaine de travail pour le « reporting », une catégorie large qui regroupe la lecture des images, la dictée et la vérification finale.
Pour les examens plus complexes, la part d’écriture augmente vite. Une étude suisse portant sur plus de 100 000 examens TDM (Sexauer, J Imaging 2022) s’est appuyée sur les horodatages du RIS pour estimer le temps de dictée. La durée moyenne se situait autour de 16 minutes, et 17,9 minutes pour une TDM abdominale.
Le tableau n’est donc pas « l’écriture absorbe tout », mais plutôt « l’écriture et tout ce qui l’entoure prend au moins autant de temps que l’analyse des images ». Et c’est encourageant, car c’est précisément le genre de travail dans lequel les modèles de langage actuels sont forts : nettoyer un texte, en garder la structure et mettre une dictée en forme.
L’IA appliquée aux images demande un parcours plus long
L’IA qui interprète les images existe déjà et peut être cliniquement utile dans certains flux de travail. Mais une interprétation large et fiable des images reste un parcours plus lourd. Une fracture manquée, un faux positif lors d’un dépistage pulmonaire, un nodule mal classé : ce sont des décisions cliniques aux conséquences cliniques. Les obstacles réglementaires sont donc plus élevés, la validation plus lourde, et l’intégration avec le PACS et le RIS plus lente.
C’est parfaitement légitime. Cela signifie aussi qu’il faudra encore des années avant que cette couche soit présente dans chaque service comme elle devrait l’être. Pendant ce temps, les radiologues rédigent des comptes rendus chaque jour, et l’IA peut déjà y apporter de la valeur sans reprendre l’interprétation primaire des images ni le diagnostic. Parce que le texte du compte rendu reste lui-même une communication clinique, toute modification potentielle du sens doit être traitée comme risquée.

Utile avant d’être magique
Il serait facile de rendre Revelar spectaculaire en laissant un modèle réécrire constamment des comptes rendus entiers. Ce serait aussi risqué.
Nous partons d’une idée plus modeste : aider sur les parties du compte rendu où le radiologue reste clairement aux commandes. Le modèle propose, corrige et structure. L’utilisateur voit chaque modification et décide si elle est appliquée.
C’est plus lent à construire. Il faut des limites de modification claires, une étape d’approbation, une manière simple d’annuler les modifications et des tests rigoureux. Mais c’est la forme que nous jugeons fiable pour un vrai travail clinique, et c’est celle avec laquelle nous pouvons déjà commencer aujourd’hui.
Architecture actuelle
Trois couches entre la dictée et le compte rendu
Chaque modification d’un compte rendu clinique traverse trois couches, chacune avec une règle plus stricte sur ce qui peut être appliqué automatiquement et ce qui attend le radiologue.
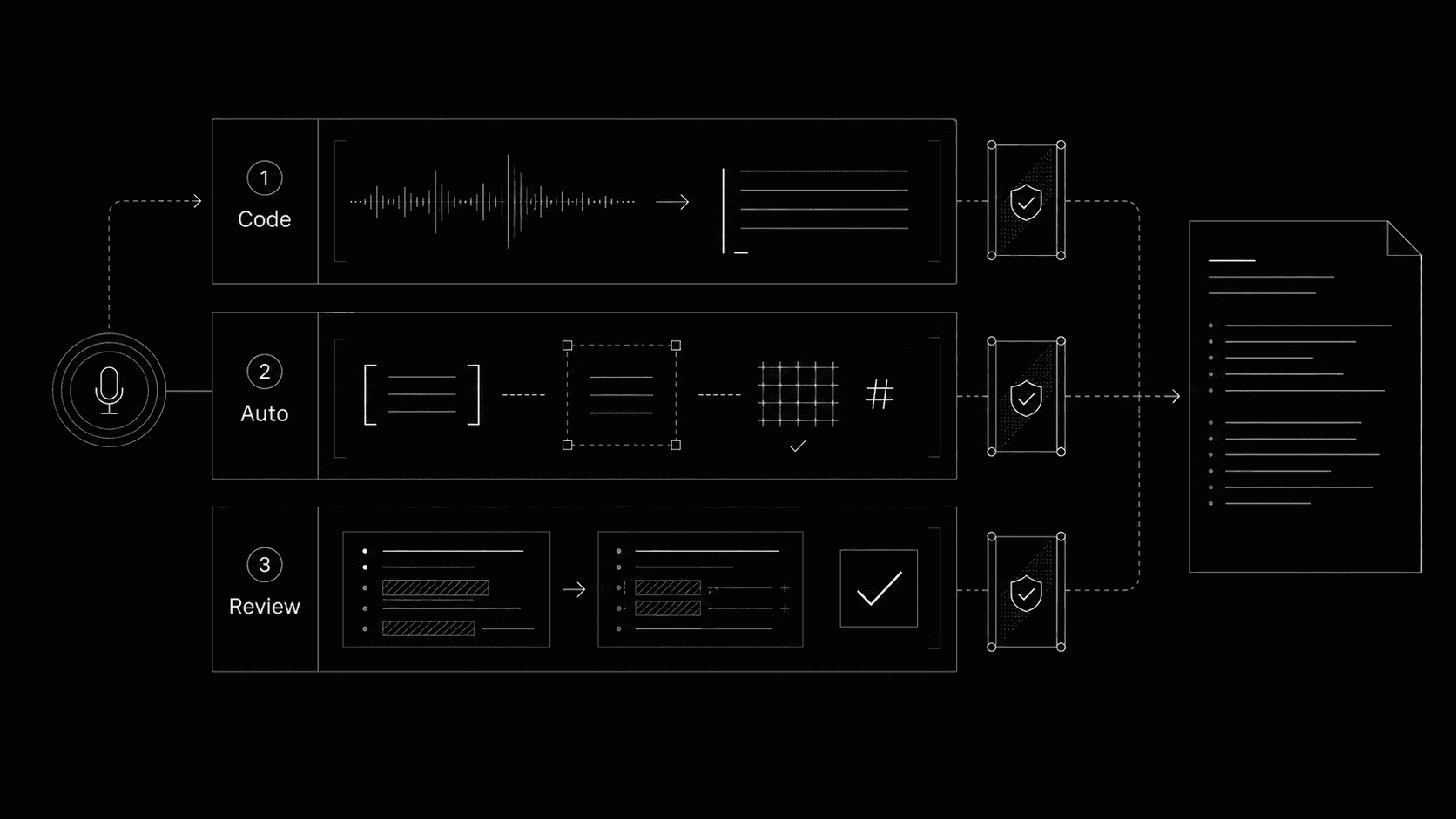
Un compte rendu de radiologie est une communication clinique. Les médecins demandeurs, les parcours de soins et l’imagerie de suivi dépendent de sa formulation exacte. Nous ne pouvons pas laisser un modèle le réécrire à sa guise. Nous ne pouvons pas non plus demander au radiologue de relire chaque virgule que l’assistant ajuste. Nous avons donc construit trois couches, chacune avec son propre niveau de confiance.
Plus une modification touche au sens clinique, plus elle doit être relue avant d’être intégrée au compte rendu.
- 01DéterministeJuste après la dictée, sans modèle
Nettoyage déterministe juste après la dictée
Quand le radiologue utilise une commande de mise en forme explicite, comme « nouvelle ligne », ce n’est pas une interprétation clinique, c’est une commande envoyée à l’éditeur. L’éditeur l’exécute directement. Le texte dicté lui-même est aussi inséré dans le compte rendu par le code, pas par un modèle, donc rien n’est inventé à ce stade.
- Ce qu’elle fait
- Insère le texte dicté dans l’éditeur et exécute les commandes vocales de mise en forme, comme point, nouvelle ligne ou nouveau paragraphe, à l’emplacement du curseur.
- Ce qu’elle bloque
- Ne peut pas reformuler, résumer, classer ni corriger un contenu médical. Aucun modèle n’intervient dans cette couche.
- 02Application automatiqueDans le segment fraîchement dicté, pilotée par un modèle
Application automatique sous garde-fous structurels
Un modèle de correction examine uniquement le segment fraîchement dicté, avec le compte rendu environnant comme contexte. Il peut appliquer automatiquement de petites corrections, mais seulement s’il déclare explicitement que la modification est sûre et ne change pas le sens clinique. Notre code ne décide jamais de ce qui est sûr en lisant les mots ; il fait uniquement respecter les conditions structurelles autour de la modification.
- Ce qu’elle fait
- Applique une correction automatiquement lorsque le modèle renvoie safeToAutoApply: true et wouldChangeClinicalMeaning: false, que l’ancre (la position exacte dans le texte) correspond, que le hash du compte rendu (empreinte numérique de l’état actuel) est à jour et que la modification n’est pas une réécriture large.
- Ce qu’elle bloque
- Ne peut pas réécrire le compte rendu entier, sortir du segment dicté, ignorer un hash périmé, ni appliquer quoi que ce soit quand le modèle hésite. Tout ce qui échoue à un garde-fou est bloqué ou redirigé vers la revue explicite.
- 03RevueToujours, en cas de doute
Revue dans le texte et approbation explicite
Tout ce dont le modèle n’est pas certain, tout ce qui se trouve hors d’un segment fraîchement dicté et chaque réécriture complète apparaît sous forme d’avant-après clair pour le radiologue. L’utilisateur accepte ou refuse chaque modification. Chaque décision (appliquée, refusée, bloquée) est enregistrée comme une trace structurée de modification qui forme la continuité de l’exécution.
- Ce qu’elle fait
- Affiche les modifications directement dans l’éditeur, présente des cartes de revue dans l’assistant et enregistre les décisions d’acceptation, de refus et de blocage par rapport au hash de l’éditeur.
- Ce qu’elle bloque
- Ne peut pas appliquer automatiquement. Ne peut pas contourner la vérification de fraîcheur du hash. Ne peut pas inventer du texte que le modèle n’a jamais proposé via un appel structuré.
Pourquoi trois couches
Deux raisons : la sécurité clinique et la réglementation qui l’entoure. Un compte rendu de radiologie est traité comme une communication clinique, et un logiciel qui en change le sens automatiquement touche à une limite que le MDR européen et l’AI Act prennent au sérieux. Découper le travail en déterministe, application automatique et revue garde les décisions risquées visibles et les corrections mécaniques rapides.
Chaque couche est aussi conçue pour laisser une trace. Chaque décision de modification produit une trace structurée avec le hash de l’éditeur, la source de la décision et l’indication que le contenu a réellement changé ou non. Un radiologue peut toujours reconstruire ce qui s’est vraiment passé dans son compte rendu.
Le plus difficile est la couche du milieu
La première couche est simple à vérifier : l’éditeur insère ce qui a été dicté. La troisième est simple à défendre : le radiologue approuve. La couche difficile est celle du milieu, où le système décide si une correction est suffisamment routinière pour ne pas interrompre le radiologue.
La partie sémantique de cette décision appartient au modèle. Pour chaque modification exacte, il doit indiquer si la correction peut être appliquée automatiquement et si elle pourrait changer le sens clinique. L’application encadre ensuite l’exécution : le hash du compte rendu doit être à jour, l’ancien texte doit correspondre exactement, la modification doit rester dans le segment fraîchement dicté, le schéma doit être valide, les modifications ne peuvent pas se chevaucher et les réécritures larges sont bloquées. Si une de ces conditions échoue, rien n’est appliqué automatiquement.
C’est cette affirmation que nous devons prouver. Nous la testons avec un système d’évaluation par couches : cas cliniques de sécurité protégés, jeux d’essai réalistes de dictée de compte rendu, rejeux d’enregistrements réels, comparaisons de fournisseurs, comparaisons de modèles et exécutions fragmentées de longues dictées. Notre principal indicateur de sécurité est le taux de modifications cliniques automatiques non sûres. La latence, le coût et la précision générale ne comptent qu’une fois cet indicateur stable et propre.
Ce qui suit est un instantané de l’endroit où cette ligne se trouve aujourd’hui.
Système d’évaluation
Comment nous testons le nettoyage de dictée
Pour chaque correction automatique, nous posons la même question pratique : aide-t-elle le radiologue sans modifier le sens clinique à son insu ?
Nous le testons en plusieurs étapes. D’abord, nous utilisons un ensemble clinique protégé avec des exemples sensibles : gauche versus droite, présence ou absence d’une anomalie, mesures, classifications, termes anatomiques, notation par segment et comptes rendus déjà corrects. Ces derniers ne doivent pas être modifiés.
Nous testons aussi des exemples de dictée réalistes. Ils montrent si le système trouve des corrections utiles, comme des erreurs de dictée, des répétitions ou des formulations maladroites, sans aller trop loin.
Nous testons ensuite les conditions de travail réelles : longues dictées qui arrivent par morceaux, rejeu d’enregistrements, exemples multilingues, comparaison des fournisseurs de transcription, vitesse, coût et qualité des différents modèles.
Chaque test produit le même type de compte rendu : les modifications proposées par le modèle, celles appliquées automatiquement, celles envoyées en revue, celles bloquées ou ignorées, et pourquoi.
Nous ne cherchons donc pas seulement à savoir si le modèle a souvent raison. Nous vérifions surtout si le système fait gagner du temps aux radiologues sans appliquer à leur insu une modification importante sur le plan clinique.
Nous utilisons ces évaluations pour décider si une nouveauté est suffisamment sûre pour être utilisée dans le produit, pas comme chiffre marketing. Un nouveau modèle, un nouveau fournisseur ou une nouvelle catégorie de corrections automatiques n’entre en considération que si les cas cliniques protégés et les exemples de dictée réalistes restent tous les deux propres.
Dernière suite par défaut
La configuration actuelle a réussi la dernière suite post-dictée, avec des cas synthétiques de sécurité et des cas dérivés d’enregistrements réels.
Scénarios cliniques protégés
L’ensemble de sécurité couvre les changements sensibles comme latéralité, négation, mesure, classification, anatomie, notation et cas où rien ne doit être modifié.
Modifications cliniques automatiques non sûres
Dans le dernier instantané large par défaut, aucune modification automatique n’a changé le sens clinique à l’insu de l’utilisateur.
Pourquoi GPT-5.4 mini est notre choix par défaut
Sur la suite post-dictée actuelle de 25 cas, GPT-5.4 mini et GPT-5.5 franchissent toutes les barrières. Mini reste notre choix par défaut parce qu’il obtient le même score avec un coût et une latence nettement plus bas ; Gemini coûtait moins que GPT-5.5 mais a manqué un cas de sécurité.
RéussiteUn cas réussit lorsqu’aucune modification automatique ne change le sens clinique à l’insu de l’utilisateur et que chaque modification proposée, application automatique et décision de revue est correcte.
Graphique : dernière mesure pour chaque modèle sur la même suite. Archive d’évaluation : 816 cas sur 39 configurations en 93 exécutions. Instantané du 2026-05-10.
Où nous en sommes
Nous sommes une petite équipe qui démarre, sans financement externe. Cela conditionne tout : nous construisons Revelar pas à pas, en restant centrés sur ce qui aide réellement les radiologues en pratique et sur ce que la réglementation européenne attend de nous.
Deux cadres dessinent la limite supérieure de ce que nous pouvons mettre en service. Le règlement relatif aux dispositifs médicaux (MDR) régit les logiciels à usage clinique, et l’AI Act ajoute des exigences propres aux systèmes d’IA, particulièrement en contexte de santé. Tous deux tirent dans la même direction : sécurité vérifiable, traçabilité et une décision finale toujours prise par un humain. Les trois couches ci-dessus ont été conçues exactement pour cela, et notre système d’évaluation a été bâti pour rendre ces propriétés testables plutôt que simplement affirmées. La conformité fait pour nous partie du produit, pas une case à cocher à la fin.
Notre prochain jalon n’est pas un lancement commercial, mais un pilote ciblé avec des radiologues qui souhaitent valider le flux de travail avec nous sur de vrais parcours de compte rendu. Ce que nous y apprendrons façonnera directement les capacités prêtes pour un déploiement plus large, et celles qui demanderont encore du travail avant de mériter ce passage.
Nous construisons un espace de compte rendu où l’IA reste proche du radiologue, apporte de la valeur dans les petits moments et est évaluée assez profondément pour que chaque nouvelle capacité mérite sa place.
Si cette direction vous parle, ou si vous êtes radiologue et souhaitez avancer avec nous, n’hésitez pas à m’écrire. Un échange de ce genre compte beaucoup pour nous à ce stade.