Wat we elke dag in de praktijk vaststellen: in radiologie is de diagnose zelden de grootste tijdrover. Beelden beoordelen en tot een diagnose komen gaat vaak verrassend snel. Het bijhorende verslag zorgvuldig formuleren, nalezen en handmatig bijwerken kost doorgaans meer tijd.
De spraakherkenning die vandaag op veel radiologieafdelingen wordt gebruikt, doorgaans Dragon Medical, SpeechMagic of SpeechKit, of een andere medische spraakmotor ingebouwd in het RIS, het PACS of de rapportagesoftware, is inmiddels uitstekend. Ze volgt de stem van de radioloog moeiteloos. Toch zien we elke dag dezelfde voorspelbare fouten handmatig gecorrigeerd worden, verslag na verslag. Daarbovenop komt gestructureerd rapporteren (structured reporting): een sjabloon handmatig kiezen, in het juiste veld klikken, dat veld inspreken, doorklikken naar het volgende, veld per veld.
Elke handeling afzonderlijk kost weinig tijd. Samen kosten ze iets wat je niet wilt opofferen: aandacht voor de beelden zelf. De radioloog is in gedachten nog deels bezig met de formulering, terwijl die volledig op de beelden gericht zou moeten zijn. We zien dit bij collega's in opleiding even sterk als bij ervaren radiologen die al twintig jaar dagelijks dicteren.
Het verslag is meer werk dan het lijkt
Wat de literatuur laat zien is genuanceerder dan de slogan "radiologen kijken de hele dag naar beelden". Lee en collega's (Curr Probl Diagn Radiol, 2017, online gepubliceerd in 2016) observeerden op een academische neuroradiologiewerkplek dat de primaire fellow (radioloog in opleiding) ongeveer 54% van de tijd aan beeldinterpretatie besteedde en 20% aan niet-beeldtaken zoals telefoongesprekken, consulten en het kiezen van het juiste onderzoeksprotocol. De Australische en Nieuw-Zeelandse personeelscensus uit 2020, met meer dan duizend radiologen, kwam uit op ongeveer 49% van de werkweek voor "reporting", een brede categorie die beeldbeoordeling, dictatie en eindcontrole omvat.
Voor complexere onderzoeken neemt het schrijfwerk snel toe. Een Zwitserse studie op meer dan 100.000 CT-onderzoeken (Sexauer, J Imaging 2022) gebruikte tijdstempels uit het RIS om de dictatietijd te schatten. De gemiddelde duur lag rond 16 minuten, met 17,9 minuten voor een abdominale CT.
Het beeld is dus niet dat schrijven alles overheerst, maar wel dat schrijven en alles eromheen minstens zoveel tijd vraagt als het kijken zelf. Dat is bemoedigend, want het is precies het soort werk waarin moderne taalmodellen sterk zijn: tekst vlot opschonen, structuur bewaken en een dictaat in de juiste vorm gieten.
AI voor beeldinterpretatie vraagt een langer traject
AI die beelden zelf interpreteert bestaat al en is in bepaalde workflows klinisch nuttig. Maar brede, betrouwbare beeldinterpretatie is een zwaarder traject. Een gemiste fractuur, een fout-positieve bevinding op een longscreening, een verkeerd geclassificeerde nodulus (kleine ronde afwijking): het zijn klinische beslissingen met klinische gevolgen. De regelgevende horden liggen hierdoor hoger, de validatie is zwaarder en de integratie met PACS en RIS verloopt trager.
Dat is volkomen terecht. Het betekent ook dat het nog jaren zal duren voor die laag in elke kliniek staat zoals het hoort. Ondertussen schrijven radiologen elke dag verslagen, en daar kan AI vandaag al waarde leveren zonder de primaire beeldinterpretatie of diagnose over te nemen. Omdat verslagtekst zelf klinische communicatie blijft, behandelen we elke mogelijke betekeniswijziging als risicovol.

Eerst nuttig, dan indrukwekkend
Het zou eenvoudig zijn om Revelar indrukwekkend te laten aanvoelen door een model voortdurend hele verslagen te laten herschrijven. Het zou ook risicovol zijn.
Wij vertrekken vanuit een bescheidener idee: ondersteunen op die plekken in de verslaggeving waar de radioloog volledig de controle behoudt. Het model stelt voor, schoont op en structureert. De gebruiker ziet elke wijziging en beslist of die wordt toegepast.
Dat vraagt meer ontwikkeltijd. Het vereist scherpe grenzen voor wijzigingen, een goedkeuringsstap, een eenvoudige manier om wijzigingen ongedaan te maken en zorgvuldig testen. Maar dat is de vorm die wij vertrouwen voor echt klinisch werk, en de vorm waarmee we vandaag al kunnen starten.
Huidige architectuur
Drie lagen tussen dictatie en verslag
Elke wijziging aan een klinisch verslag passeert drie lagen, elk met een strengere regel over wat automatisch mag worden toegepast en wat op de radioloog wacht.
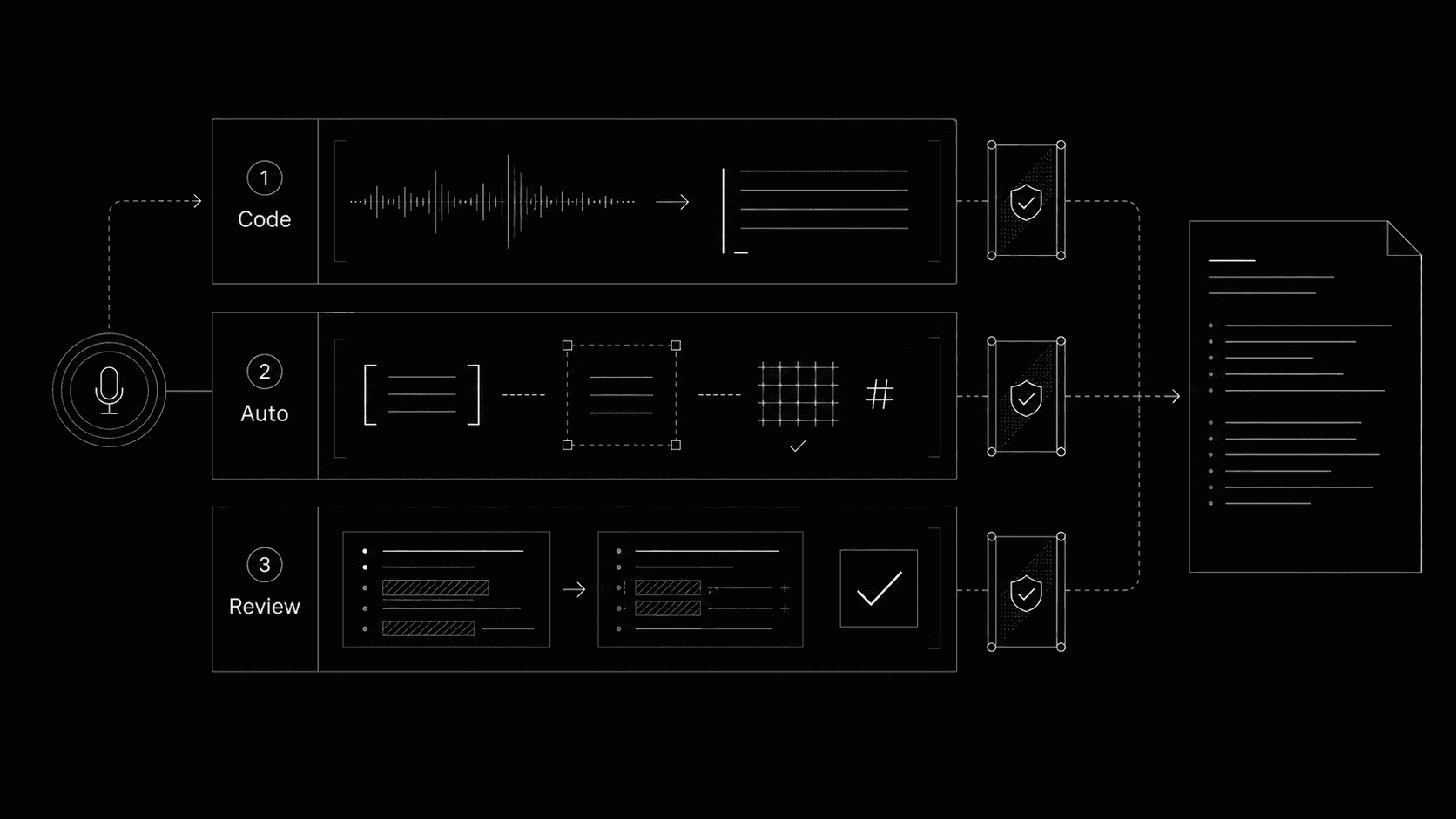
Een radiologieverslag is klinische communicatie. Aanvragende artsen, patiëntentrajecten en vervolgbeeldvorming hangen samen met de exacte formulering. We kunnen het verslag dus niet zomaar door een model laten herschrijven. We kunnen ook niet van de radioloog verwachten dat hij elke komma naleest die de assistent bijwerkt. Daarom hebben we drie lagen gebouwd, elk met een eigen niveau van vertrouwen.
Hoe dieper een wijziging in de klinische betekenis ingrijpt, hoe meer ogen ze moet passeren voor ze in het verslag terechtkomt.
- 01DeterministischVlak na dictatie, zonder model
Deterministische opschoning vlak na dictatie
Wanneer de radioloog een expliciet opmaakcommando gebruikt, zoals "nieuwe regel", is dat geen klinische interpretatie maar een bediening van de editor. De editor voert dat rechtstreeks uit. De gedicteerde tekst zelf wordt ook door code ingevoegd, niet door een model, zodat er op deze laag niets wordt verzonnen.
- Wat deze laag doet
- Voegt gedicteerde tekst in de editor in en voert spraakgestuurde opmaakcommando's uit, zoals punt, nieuwe regel of nieuwe alinea op de cursorpositie.
- Wat deze laag blokkeert
- Kan niet herformuleren, samenvatten, classificeren of medische inhoud corrigeren. Op deze laag draait geen enkel model.
- 02Automatisch toepassenBinnen het zojuist gedicteerde segment, door een model
Automatisch toepassen met structurele controles
Een correctiemodel kijkt uitsluitend naar het zojuist gedicteerde segment, met de omringende verslagtekst als context. Het mag kleine correcties automatisch toepassen, maar alleen wanneer het expliciet verklaart dat de wijziging veilig is en de klinische betekenis niet verandert. Onze code beoordeelt nooit op basis van de woorden of een wijziging veilig is; ze handhaaft uitsluitend de structurele voorwaarden rond de wijziging.
- Wat deze laag doet
- Past een correctie automatisch toe wanneer het model safeToAutoApply: true en wouldChangeClinicalMeaning: false teruggeeft, het anker (de exacte tekstpositie) overeenkomt, de verslag-hash (digitale vingerafdruk van de huidige verslagstaat) actueel is en het geen brede herschrijving betreft.
- Wat deze laag blokkeert
- Kan het volledige verslag niet herschrijven, kan niet buiten het gedicteerde segment treden, kan geen verouderde hash negeren en past niets toe wanneer het model twijfelt. Wat de controles niet passeert, wordt geblokkeerd of doorgestuurd naar expliciete review.
- 03ReviewAltijd, in geval van twijfel
Review in de tekst en expliciete goedkeuring
Alles waarover het model niet zeker is, alles buiten een zojuist gedicteerd segment, en elke volledige herschrijving verschijnt als een duidelijke vergelijking (voor versus na) voor de radioloog. De gebruiker aanvaardt of weigert elke wijziging. Elke beslissing (toegepast, geweigerd, geblokkeerd) wordt vastgelegd als een gestructureerd wijzigingsrecord, dat het continuïteitsspoor van de run vormt.
- Wat deze laag doet
- Toont de wijzigingen direct in de editor, toont reviewkaarten in de assistent en logt acceptaties, weigeringen en blokkeringen tegen de editor-hash.
- Wat deze laag blokkeert
- Kan niet automatisch toepassen. Kan de actualiteitscontrole van de hash niet omzeilen. Kan geen tekst introduceren die het model niet expliciet voorstelde via een gestructureerde modelaanroep.
Waarom drie lagen
Twee redenen: klinische veiligheid en de bijbehorende regelgeving. Een radiologieverslag wordt beschouwd als klinische communicatie, en software die de betekenis automatisch wijzigt raakt aan een grens die de Europese MDR en de AI Act serieus nemen. Het werk opsplitsen in deterministisch, automatisch toepassen en review houdt de risicovolle beslissingen zichtbaar en de mechanische correcties snel.
Elke laag is ook ontworpen om een traceerbaar spoor na te laten. Iedere wijzigingsbeslissing levert een gestructureerd wijzigingsrecord met de editor-hash, de bron van de beslissing en de vermelding of de inhoud daadwerkelijk veranderde. Een radioloog kan altijd reconstrueren wat er precies in zijn verslag is gebeurd.
De middelste laag is de moeilijkste
Laag één is eenvoudig te verifiëren: de editor voegt in wat is gedicteerd. Laag drie is eenvoudig te verdedigen: de radioloog keurt goed. De lastige laag is de middelste, waar het systeem beslist of een correctie voldoende triviaal is om de radioloog niet te onderbreken.
Het semantische deel van die beslissing ligt bij het model. Per exacte wijziging moet het model aangeven of de correctie veilig automatisch mag landen en of ze de klinische betekenis kan veranderen. De applicatie bewaakt daarna de uitvoering: de verslag-hash moet actueel zijn, de oude tekst moet exact overeenkomen, de wijziging moet binnen het zojuist gedicteerde segment blijven, het schema moet geldig zijn, wijzigingen mogen niet overlappen en brede herschrijvingen worden geblokkeerd. Als één van die voorwaarden faalt, wordt er niets automatisch toegepast.
Dat is de claim die we moeten bewijzen. We testen ze met een gelaagd evaluatiesysteem: beschermde klinische veiligheidscases, realistische verslagdictaten, replays van echte opnames, providervergelijkingen, modelvergelijkingen en gefragmenteerde runs van lange dictaten. Onze belangrijkste veiligheidsmaatstaf is het aantal onveilige automatische klinische wijzigingen. Latentie, kosten en algemene nauwkeurigheid zijn pas relevant zodra die maatstaf schoon blijft.
Wat hierna volgt is een momentopname van waar die grens vandaag ligt.
Evaluatiesysteem
Hoe we de dictatie-opschoning testen
Bij elke automatische correctie stellen we dezelfde praktische vraag: helpt deze wijziging de radioloog, zonder ongemerkt iets aan de klinische betekenis te veranderen?
Daarom testen we in meerdere stappen. Eerst gebruiken we een vaste klinische testset met gevoelige voorbeelden. Daarin zitten onder meer links-rechtsverschillen, ontkenningen, metingen, classificaties, anatomische termen, segmentnotatie en verslagen die al correct zijn. Die laatste mogen dus niet aangepast worden.
Daarnaast testen we met realistische dictatievoorbeelden. Zo controleren we of het systeem nuttige correcties vindt, zoals dicteerfouten, herhalingen of rommelige formuleringen, zonder te ver te gaan.
We testen ook de omstandigheden waarin radiologen echt werken: langere dictaten die in stukken binnenkomen, opnieuw afgespeelde opnames, meertalige voorbeelden, verschillen tussen transcriptieproviders, snelheid, kosten en de kwaliteit van verschillende modellen.
Elke testrun levert hetzelfde soort verslag op. Daarin staat welke wijzigingen het model voorstelde, welke automatisch werden toegepast, welke eerst ter goedkeuring werden voorgelegd, welke werden geblokkeerd of overgeslagen, en waarom.
Zo beoordelen we niet alleen of het model vaak gelijk heeft. We beoordelen vooral of het systeem werk bespaart zonder klinisch belangrijke wijzigingen ongemerkt door te voeren.
We gebruiken deze evaluaties om te beslissen of iets veilig genoeg is om in het product te gebruiken. Een nieuw model, een nieuwe provider of een nieuwe categorie automatische correcties komt pas in aanmerking wanneer de gevoelige klinische testset en realistische dictatievoorbeelden allebei goed blijven.
Laatste standaardsuite
Onze huidige standaardconfiguratie slaagde in de laatste evaluatieronde na dictatie, op zowel synthetische veiligheidscases als cases afgeleid uit echte opnames.
Beschermde klinische scenario’s
De vaste veiligheidsset dekt betekenisgevoelige wijzigingen zoals lateralisatie, negatie, meting, classificatie, anatomie, notatie en cases waar niets mag worden aangepast.
Onveilige automatische klinische wijzigingen
In de laatste brede momentopname van de standaardconfiguratie veranderde geen enkele automatische wijziging ongemerkt de klinische betekenis.
Waarom GPT-5.4 mini onze huidige standaardkeuze is
Op de huidige post-dictatiesuite van 25 cases kwamen GPT-5.4 mini en GPT-5.5 allebei door elke controle. Mini blijft onze standaard omdat het dezelfde score haalt tegen veel lagere kosten en met lagere latentie; Gemini was goedkoper dan GPT-5.5 maar miste één veiligheidscase.
GeslaagdEen case slaagt wanneer geen automatische wijziging ongemerkt de klinische betekenis verandert en elke voorgestelde wijziging, automatische toepassing en review-beslissing klopt.
Grafiek: laatste meting op dezelfde suite per model. Evaluatiearchief: 816 cases over 39 configuraties in 93 runs. Snapshot van 2026-05-10.
Waar we vandaag staan
We zijn een onafhankelijk oprichtersteam en bouwen Revelar voorlopig zonder externe financiering. Dat tekent alles wat we doen: rustig, stap voor stap, met focus op wat radiologen in de praktijk echt vooruithelpt en op wat de Europese regelgeving van ons verwacht.
Twee kaders bepalen de bovengrens van wat we mogen uitrollen. De verordening medische hulpmiddelen (MDR) regelt software die klinisch wordt ingezet, en de AI Act legt bovenop daarvan specifieke eisen op aan AI-systemen, zeker in een zorgcontext. Beide trekken in dezelfde richting: verifieerbare veiligheid, traceerbaarheid en altijd een mens met de eindbeslissing. De drie lagen hierboven zijn precies daarop gebouwd, en ons evaluatiesysteem is opgezet om die eigenschappen meetbaar te maken in plaats van ze enkel te beweren. Compliance behandelen we als deel van het product, niet als een vinkje achteraf.
Onze eerstvolgende mijlpaal is geen commerciële lancering, maar een gerichte pilot met radiologen die samen met ons de werking willen valideren in echte verslagprocessen. Wat we daar leren bepaalt rechtstreeks welke functies klaar zijn voor bredere uitrol, en welke nog werk vragen voor ze die stap verdienen.
We bouwen aan een verslagomgeving waarin AI dicht bij de radioloog staat, op de kleine momenten waarde toevoegt en grondig genoeg wordt geëvalueerd zodat elke nieuwe mogelijkheid haar plaats verdient.
Herken je je in die richting, of werk je in de radiologie en wil je met ons meedenken, laat dan zeker iets weten. Zo’n gesprek betekent veel voor ons in deze fase.