What we see every day in practice is this: in radiology, the diagnosis is rarely the real time sink. Looking at the images and reaching a diagnosis can go surprisingly fast. Phrasing the report around that image, rereading it, and polishing it by hand takes more time.
The speech recognition running in many radiology departments today, usually Dragon Medical, SpeechMagic or SpeechKit, or another medical speech engine embedded inside the RIS, the PACS, or the reporting software, has become genuinely good. It follows the radiologist's voice effortlessly. And yet every day we see the same predictable errors cleaned up by hand, report after report. On top of that comes structured reporting: manually picking a template, clicking into the right field, dictating that field, clicking to the next. Piece by piece.
Each small piece costs little on its own. Together they cost something you do not want to lose: attention to the images themselves. The radiologist's mind is half busy with "how am I going to phrase this", when it should be fully on the image. We see this in trainees as much as in experienced radiologists who have dictated daily for twenty years.
The report is more work than it looks
What the literature shows is more nuanced than the slogan "radiologists look at images all day". A time-and-motion study by Lee and colleagues (Curr Probl Diagn Radiol, 2017, published online in 2016) observed the primary fellow at an academic neuroradiology workstation spending about 54% of their time on image interpretation, and roughly 20% on non-image work such as phone calls, consultations, and protocoling (selecting the right scan protocol). The 2020 Australian and New Zealand workforce census, with more than a thousand radiologists, came in at around 49% of the work week for "reporting", a broad category that bundles image review, dictation, and final check.
For more complex studies, the writing portion grows quickly. A Swiss study on more than 100,000 CTs (Sexauer, J Imaging 2022) used RIS timestamps to estimate dictation time. The average was around 16 minutes per CT, and 17.9 minutes for an abdominal CT.
So the picture is not "writing swallows everything", but rather "writing and everything around it takes at least as much time as looking". That is encouraging, because it is exactly the kind of work modern language models are strong at: cleanly tidying text, keeping structure, casting a dictation into the right form.
AI on the images is a longer road
AI that interprets images already exists and is clinically useful in specific workflows. But broad, reliable image interpretation is a heavier path. A missed fracture, a false positive on a lung screen, a misclassified nodule: these are clinical decisions with clinical consequences. The regulatory hurdles are higher, validation is heavier, and integration with PACS and RIS is slower.
All of that is right. It also means it will take years before that layer sits in every clinic the way it should. In the meantime, radiologists write reports every day, and AI can already add value there today without taking over primary image interpretation or diagnosis. Because the report text itself remains clinical communication, every possible change in meaning must be treated as risky.

Useful before magical
It would be easy to make Revelar feel magical by letting a model constantly rewrite whole reports. It would also be risky.
We start from a smaller idea: help with the parts of reporting where the radiologist stays clearly in control. The model proposes, cleans up, and structures. The user sees every change and decides whether it is applied.
That is slower to build. It needs sharp edit limits, an approval step, an easy way to undo changes, and careful testing. But it is the shape we trust for real clinical work, and the shape we can already start with today.
Current architecture
Three layers between dictation and the report
Every change to a clinical report passes through three layers, each with a stricter rule about what may move silently and what waits for the radiologist.
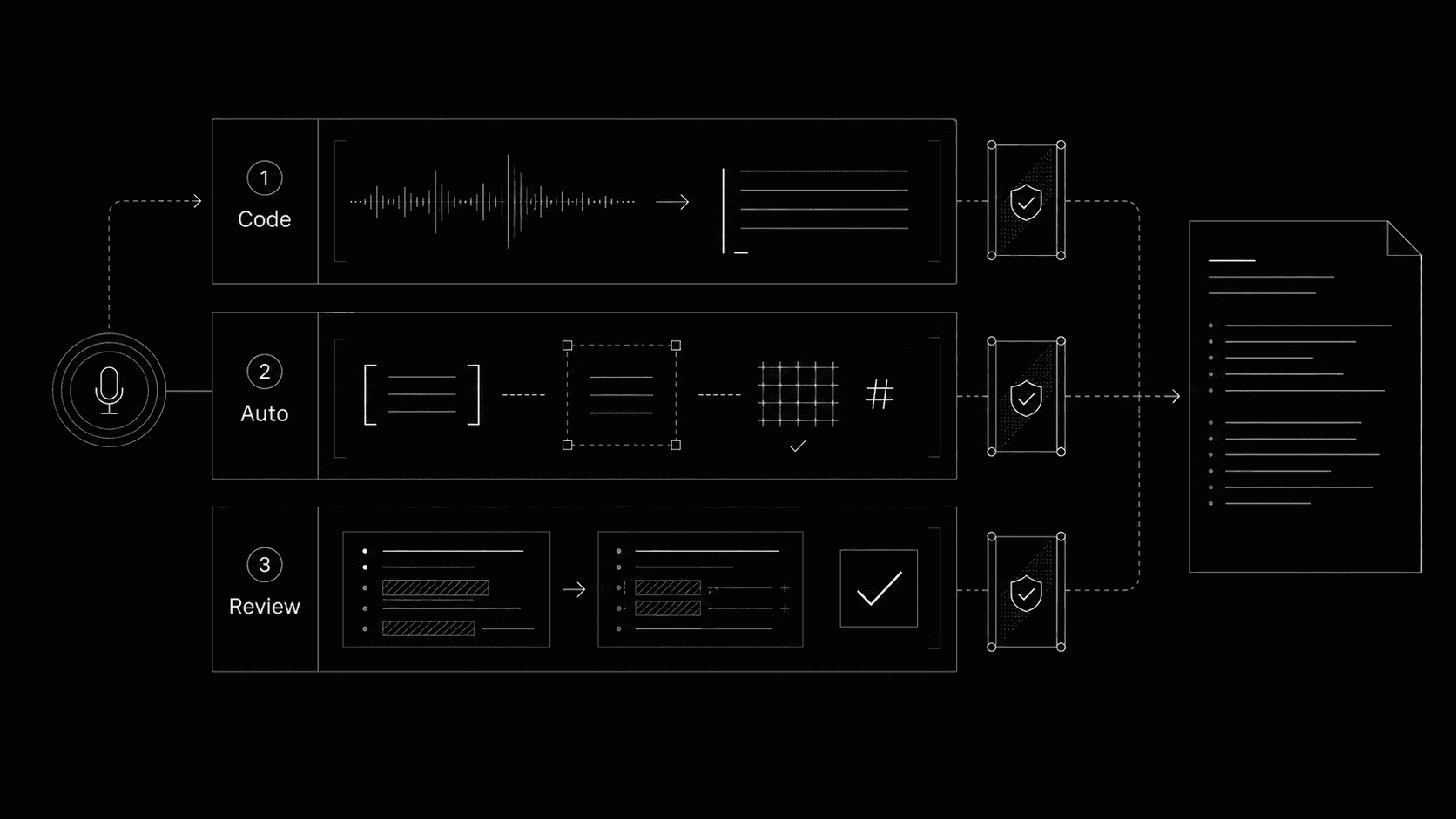
A radiology report is clinical communication. Referring physicians, patient pathways, and follow-up imaging all hang on its exact wording. We cannot let a model rewrite it freely. We also cannot ask the radiologist to read every comma the assistant tidies up. So we built three layers, each with its own level of trust.
The deeper a change reaches into clinical meaning, the more eyes it has to pass before it lands in the report.
- 01DeterministicRight after dictation, no model
Code-level cleanup right after dictation
When the radiologist uses an explicit formatting command such as "new line", that is not a clinical interpretation, it is a command to the editor. The editor executes it directly. The dictated text itself is also placed in the report by code, not by a model, so nothing is invented at this stage.
- What it does
- Inserts dictated text into the editor and executes voice-only formatting commands such as period, new line, or new paragraph at the cursor.
- What it blocks
- Cannot rephrase, summarize, classify, or correct medical content. No model runs in this layer.
- 02Silent applyInside the freshly dictated range, model-led
Silent apply with structural guards
A correction model looks only at the freshly dictated segment, with the surrounding report as context. It can apply small cleanups silently, but only when it explicitly declares the change is safe and does not alter clinical meaning. Our code never decides what is safe by reading the words; it only enforces the structural conditions around the change.
- What it does
- Applies a correction silently when the model returns safeToAutoApply: true and wouldChangeClinicalMeaning: false, the anchor (the exact text position) matches, the report hash (a digital fingerprint of the current report state) is fresh, and the change is not a broad rewrite.
- What it blocks
- Cannot rewrite the whole report, cross outside the dictated range, ignore a stale hash, or apply when the model is uncertain. Anything that fails a guard is blocked or routed to explicit review.
- 03ReviewAlways, when in doubt
In-text review and explicit approval
Anything the model is not certain about, anything outside a fresh dictated range, and every full rewrite is staged as a clear before-and-after for the radiologist. The user accepts or rejects each change. Every decision (applied, denied, blocked) is recorded as a structured edit receipt that becomes the continuity record for the run.
- What it does
- Stages the changes directly in the editor, shows review cards in the assistant, and logs accept, deny, and blocked outcomes against the editor hash.
- What it blocks
- Cannot apply silently. Cannot bypass the fresh-hash check. Cannot invent text the model never proposed through a structured model call.
Why three layers
Two reasons: clinical safety, and the regulations around it. A radiology report is treated as clinical communication, and software that quietly changes its meaning crosses a line that the EU MDR and the AI Act take seriously. Splitting work into deterministic, silent apply, and review tiers keeps the risky decisions visible and the mechanical corrections fast.
Each layer is also designed to leave a trail. Every edit decision emits a structured receipt with the editor hash, the source of the decision, and whether content actually changed. A radiologist can always reconstruct what really happened in their report.
The hardest part is the middle layer
Layer one is straightforward to verify: the editor inserts what was dictated. Layer three is straightforward to defend: the radiologist approves it. The hard layer is the one in the middle, where the system decides whether a correction is routine enough to apply without interrupting the radiologist.
The semantic part of that decision belongs to the model. It must say, for each exact patch, whether the correction is safe to auto-apply and whether it could change clinical meaning. The application then enforces the execution rules: the report hash must be fresh, the old text must match exactly, the patch must stay inside the newly dictated range, the schema must be valid, edits must not overlap, and broad rewrites are blocked. If any of these fails, nothing is applied silently.
That is the claim we need to prove. We test it with a layered evaluation system: protected clinical safety cases, realistic report-dictation fixtures, replays of real recordings, provider comparisons, model comparisons, and chunked runs of long dictations. Our primary safety metric is the rate of unsafe silent clinical changes. Latency, cost, and general accuracy only matter once that metric stays clean.
What follows is a snapshot of where that line currently sits.
Evaluation system
How we test the dictation cleanup
For every automatic correction, we ask one practical question: does this help the radiologist without silently changing clinical meaning?
We test that in several layers. First, we use a fixed protected clinical set with examples where meaning is fragile: left versus right, present versus absent findings, measurements, classifications, anatomy, segment notation, and reports that are already correct and should not be changed at all.
We also test realistic dictation examples. Those cases show whether the system catches useful fixes, such as dictation slips, repeated words, or rough phrasing, without crossing clinical boundaries.
Then we test the conditions radiologists actually work in: longer dictations that arrive in chunks, recording replays, multilingual stress cases, transcription provider comparisons for quality and speed, and model comparisons for safe routing, useful corrections, latency, and cost.
Every run produces the same kind of report: which changes the model proposed, which were applied automatically, which were sent to review, which were blocked or skipped, and why.
That lets us judge more than whether the model is often right. The real question is whether the system saves radiologists work without silently applying a clinically meaningful change.
We use these evaluations to decide whether something is safe enough to ship in the product, not as a marketing number. A new model, provider, or category of automatic correction only becomes a candidate when the protected clinical cases and realistic dictation examples both remain clean.
Latest default suite
The current default passed the latest post-dictation suite across synthetic safety cases and cases derived from real recordings.
Protected clinical scenarios
The fixed safety set covers meaning-sensitive report changes such as laterality, negation, measurement, classification, anatomy, notation, and cases where nothing should be edited.
Unsafe silent clinical changes
In the latest broad default snapshot, no automatic change silently altered clinical meaning.
Why GPT-5.4 mini is our current default
On the current 25-case post-dictation suite, GPT-5.4 mini and GPT-5.5 both cleared every gate. Mini stays our default because it reaches the same score at much lower cost and lower latency; Gemini was cheaper than GPT-5.5 but missed one safety case.
PassA case passes when no automatic edit silently changes clinical meaning, and every proposed edit, silent apply, and review decision is correct.
Chart: latest same-suite measurement per model. Eval archive: 816 cases across 39 configurations over 93 runs. Snapshot 2026-05-10.
Where we are today
We are a small, just-started team without outside funding. That shapes everything: we build Revelar carefully, step by step, focused on what actually helps radiologists in practice and on what European regulation expects from us.
Two frameworks set the upper limit of what we may ship. The Medical Device Regulation (MDR) governs software used clinically, and the AI Act adds specific requirements for AI systems, especially in healthcare. Both pull in the same direction: verifiable safety, traceability, and a human always making the final call. The three layers above were designed exactly for that, and our evaluation system was built to make those properties testable rather than declared. We treat compliance as part of the product, not a checkbox at the end.
Our next milestone is not a commercial launch, but a focused pilot with radiologists who want to validate the workflow with us on real reporting flows. What we learn there directly shapes which capabilities are ready for broader use, and which need more work before they earn that step.
We are building toward a reporting workspace where AI stays close to the radiologist, adds value in the small moments, and is evaluated deeply enough that every new capability earns its place.
If that direction resonates with you, or if you work in radiology and want to think along with us, please reach out. A conversation like that means a great deal at this stage.